How Dream11 leverages Causal Inference to make data-driven decisions
- Published on
Since inception, Dream11 has fostered a culture of being data-obsessed; it's in our DNA. At the Stadium (the Dream11 office), you will always find data at the core of every decision-making process.
As a sports technology company, which is user first, we conduct hundreds of experiments to offer our users world-class experiences. However, conducting clean experiments isn’t always feasible. Given this challenge, and to stay ahead of the curve, we built our very own AI-based Causal Inference Platform, which leverages existing data to determine causal impact. We’ve leveraged Causal Inference to drive critical business decisions. Continue to read this blog to understand Dream11’s AI & data-centric journey.
Causality
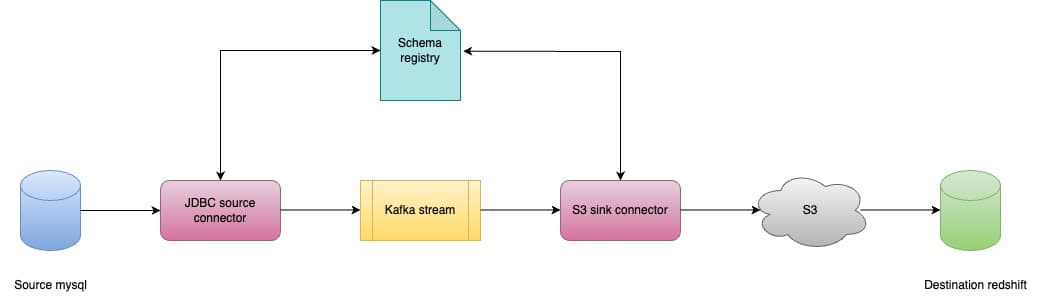
In A/B experiments, users are randomly assigned to one of the two or more variants - the current product version ‘A’ (called the control group or CG) or the new product version ‘B’ (called the treatment group or TG). The winning variant is determined based on the performance of CG and TG across various business metrics (e.g. revenue, engagement etc), and is then rolled out to all.
The random allocation of users into TG and CG removes any pre-existing differences between the two. It provides the capability for like-for-like comparisons (See image below). As a result, any differences in performance of business metrics between TG and CG are unlikely to have been caused by factors (like more power users in one of the variants, seasonality, other product changes, etc.) other than the new product version, making it attributable to the new product version. This attribution is also called causality (i.e., the latest product version causes the change in business metrics). A/B Experiments are considered the gold standard to measure the causal impact of a product change on a business metric.

Challenges with current experimentation techniques
Often clean A/B experiments are not possible. For example,
- Some A/B experiments can result in a bad user experience. For eg. we wanted to know how experiencing a deposit failure influences customers on Dream11 and rank the severity of various types of deposit failures. Running an A/B experiment would entail intentionally failing the deposit of a customer in TG, which would negatively impact the customer experience
- Some A/B experiments are not cleanly run. E.g. TG significantly overlaps with another experiment’s TG. Clear attribution is impossible as both experiments move the same metric
- Not everyone in TG may have received the treatment - E.g. emails were sent only to TG, but not everyone opened it. Comparing those who opened the email in the TG with CG who didn’t get an email leads to selection bias.
- Treatment effects may vary across subgroups, and the best approach for each subgroup is unknown. For example, some users may prefer cross-selling, while others dislike it, and some remain indifferent. Understanding the treatment's impact on individual users is essential, rather than seeking a one-size-fits-all solution for all users.
- Experiments may be time-consuming, and we need to learn from existing data
In such situations, we must use alternative approaches to estimate the (causal) impact.
AI-based Causal Inferencing
Causal Inferencing leverages AI to determine the causal impact i.e. whether X (product feature) causes change in Y (business metrics) and by how much. Causal Inference leverages observational data i.e., existing data, and hence doesn’t require running the experiment.
Let’s continue with one of the examples mentioned above. Dream11 wanted to know how experiencing a deposit failure influences customers’ money spent on the platform and accordingly rank the severity of types of deposit failures. Causal Inference was used to compare two groups that have attempted at least 1 Deposit:
- TG: Faced a Deposit issue (Delay or failure in a transaction) but did not report it
- CG: Did not face any issues
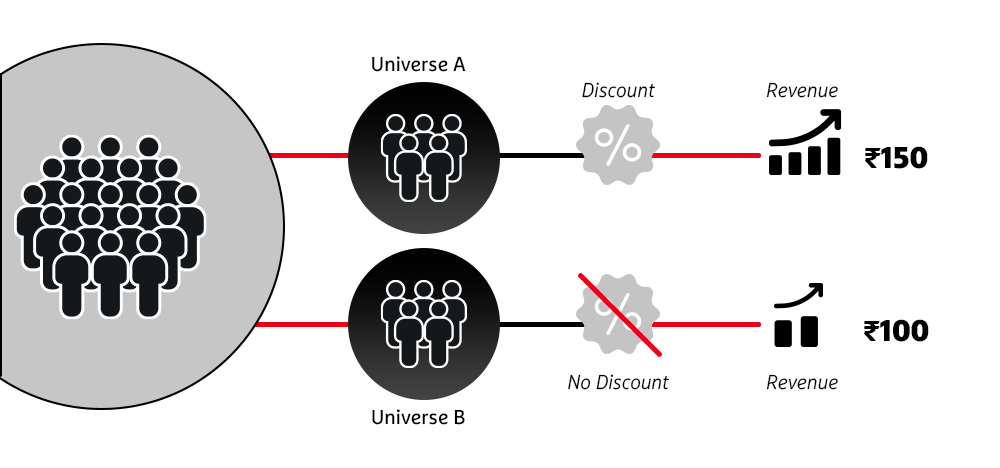
Unlike A/B experimentation, the TG and CG aren’t randomly allocated, leading to pre-existing differences, e.g. tenure of the user playing on the app. Although the TG exhibited lower spending on the platform, this couldn’t solely be attributed to deposit failures. It might also be due to new users not knowing where to report an issue. These pre-existing differences that influence the outcome metric are called confounders.
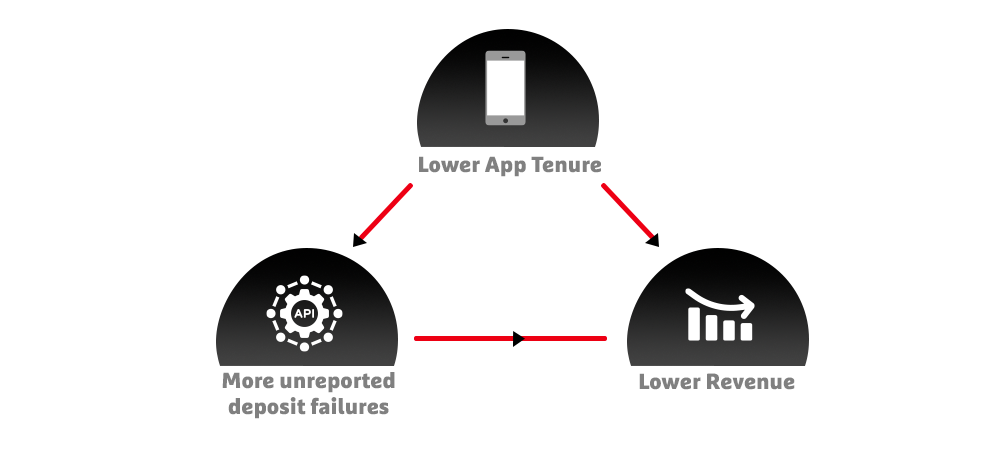
The causal inference was carried out as per the following steps:
- Identify & form groups: We identified two distinct groups - the Treatment Group (TG), comprising of individuals who encountered a deposit failure but didn’t report it, and the Control Group (CG), consisting of those who did not experience this issue
- Observe & analyse: We examined the outcomes for each group after a specific period, like their money spent on the platform during Week 4. For TG, the focus was on the expenditure in Week 4 following the deposit failure. For CG, it was the amount spent in Week 4 without encountering a deposit failure.
- Counterfactual estimation: To understand the potential outcomes if individuals were in the opposite group, advanced AI algorithms were employed. Confounders played a pivotal role in this estimation process.
- Compare apples to apples: To assess the real impact of the deposit failure, we subtract the money spent by the same person in the TG and CG. This approach helps compare how the deposit failure directly influenced their spending. Find the average impact: Finally, we take the average impact of the deposit failure on money spent for the entire group. This provides insights into the overall average influence of the deposit failure on everyone.
The values in red are called potential outcomes or counterfactuals. These are unobserved, and approximating them using AI is the crux of any causal inference algorithm. “Matching” is a popular causal inference algorithm. Besides this, various other well-established advanced algorithms exist.
By leveraging Causal Inference, Dream11 estimated the impact of deposit failures. Following this, Dream11 ran Causal Inference across multiple categories of deposit issues to quantify the severity of each issue and prepare a prioritized containment strategy. Causal Inference proved instrumental in guiding the team towards data-driven prioritization of resources, where alternative solutions fell short.
Causal Inference Platform at Dream11
The Product and Data teams at Dream11 faced a widespread challenge in determining causal impacts when experiments were unfeasible. This included assessing the impact of experiments in areas of -
- Mega contests
- Rewards
- Unsubscription of notifications
- Deposits and Withdrawals
- Brand campaigns
- Overlapping experiments
- Changing contest templates etc
Causal Inference is a field that has undergone extensive study over the years, showcasing notable advancements; however, it remains an evolving and dynamic area of research. In recognition of its importance, Gartner rated Causal AI among the top emerging technologies in 2023. Consequently, limited products are available in the market or open-source communities for causal inference. The key shortcomings observed in most recognized products include:
Lack of UI-based platform for low-code personas like Analysts, PM, Marketing
Inability to scale to handle large-sized data. Dream11’s datasets often exceed 100s of gigabytes.
To overcome these challenges, Dream11 developed an internal Causal Inference Platform for Analysts with key capabilities including -
Self-serviceable, UI-based solution
Enables evaluation of causal relations across binary, multi-class and continuous problems
- E.g. Binary problem: Impact of depositing v/s not depositing
- Multi-class problem: Impact of depositing amounts Rs 1 - 20, Rs 21 - 50, Rs 50 - 100, > Rs 100)
Quick run-time and ability to handle scale, by integrating with Dream11’s ML Platform that utilizes the distributed framework- Ray
Ability to achieve segmented results (e.g. across user cohorts such as new v/s power users)
Improve confidence by validating results with multiple algorithms (such as Metalearners, Matching, DML, and DR Learners). Visual results and summary for quick understanding.
To conclude, Causal Inference can transform businesses by providing a clear understanding of cause-and-effect relationships. At Dream11, we have first-hand experience of the impact of data-driven decision-making through our internal platform. Embracing this approach gives organizations the capability to make informed decisions, foster innovation, and gain a competitive edge. Causal Inference serves as a guiding beacon, illuminating the path toward more informed decision-making in a rapidly evolving world of data-driven enterprises.
To learn more about Dream11’s experimentation platform, click here