

DRS: Making high-impact & informed decisions with Dream11's In-house Experimentation Platform!
- Published on
With millions of Indian sports fans across our Dream Sports ecosystem, it takes a highly data-driven team to understand what is required for great fan engagement and ultimately making sports better through our various brands. At Dream11 too, we have been on a constant mission to provide amazing end-to-end user experiences to over 130 million sports fans with new product features and offerings that are shipped regularly.\ \ Data at the core of every decision that we take as Dreamsters. We run multiple experiments parallelly at Dream11 to evaluate a new feature or product customisation for our users. To enable better decision-making, all these experiments are run by our product and tech team on our very own in-house experimentation platform Data-Driven Review System or as we call it, DRS.
Why did we build DRS?
On the Dream11 app, the spike in the traffic can be mammoth during landmark sporting events like the IPL. With such a huge volume and large scale user activation events, the complexity of experimentation multifolds. At any given time, teams at Dream11 are running numerous parallel experiments, testing out innumerable hypotheses. Thus, there arises a need to conduct these product increment tests on an isolated set of similar users so multiple experiments don't bias each others’ results and accurately attribute the change in a data metric for every product increment.
To figure out a resolution, we played with multiple external tools for experimentation but weren’t able to find one that managed and aligned with our needs and scale. Internal teams had various custom use-cases around user sampling, assignment strategies and backend experimentation capabilities that were missing in the market, which pushed us to build our own internal platform.
How does the DRS work at Dream11
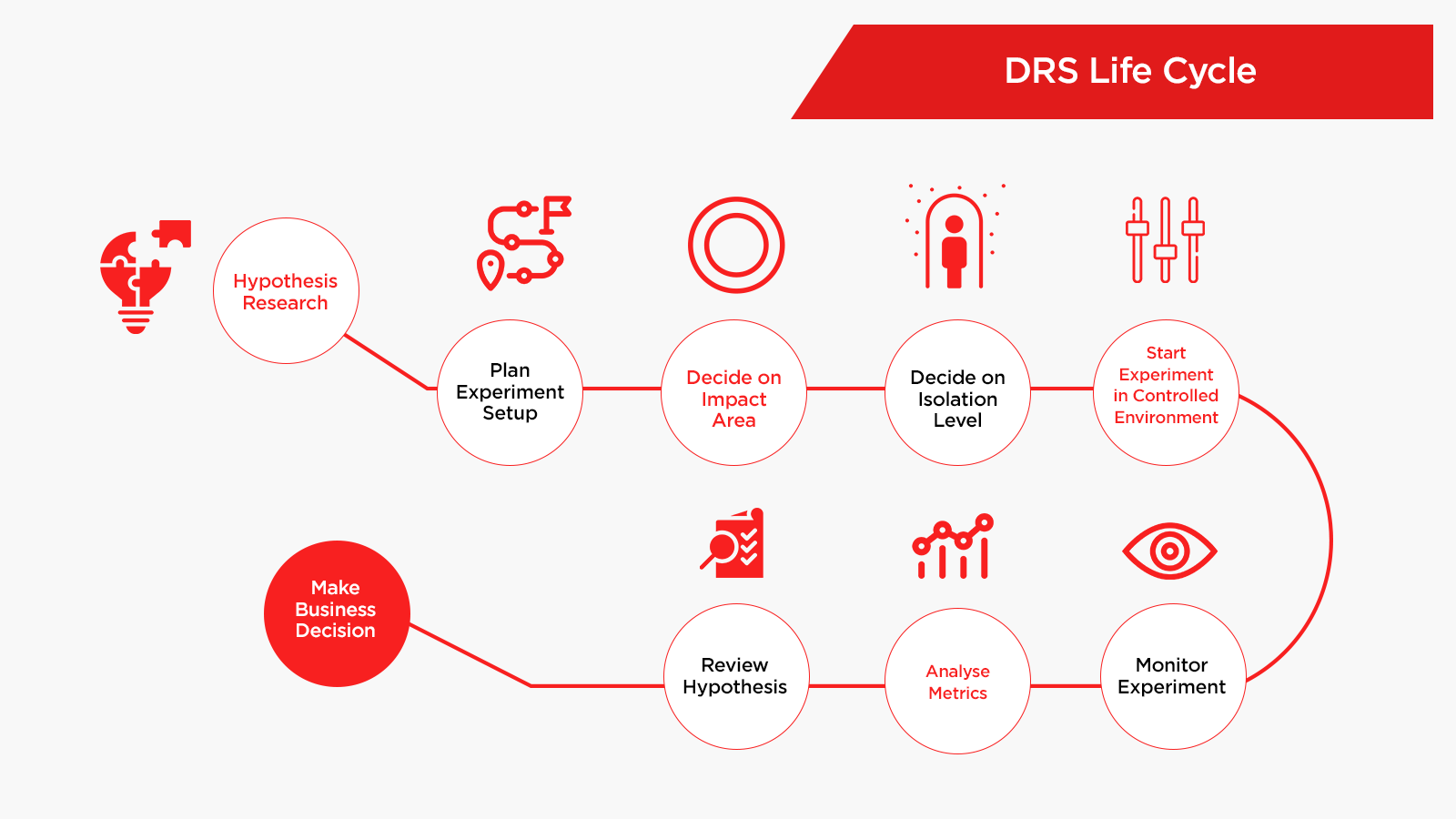
The building blocks of a DRS experiment
Type of Experiments
A DRS experiment can be one of the following types:
- Frontend
- Backend
A frontend experiment is essentially on the user interface. In simpler terms, frontend experiments are designed to experiment on cosmetic changes to your application (for example, the buttons on the app or exposure to a new feature section).
Backend experiments, on the other hand, are experiments which modify the data the user sees. It usually involves different input parameters to algorithms and business logic, driven by Application Programming Interface (API) responses.
Impact Area: Cohorts
A controlled user space is imperative in reducing the possibility of an adverse impact of an experiment on any critical business metric. This essentially means that it is necessary to restrict the impact area of the experiment.
DRS provides out-of-the-box support for internal teams through a robust and customizable Cohorting Engine. In addition to that, DRS provides support for complex sampling strategies based on user traits (which we will cover in detail below). Stakeholders can also create a static list of users to run experiments on by running queries on historic data.
In addition to the on-the-fly cohort creation, there are some user sets that are commonly used for experimentation within Dream11. The DRS platform also provides these system cohorts to stakeholders with ease. Some of them are:
- All: All Dream11 Users
- Logged In: Only Authenticated Users
- Non-Logged In: Only Non Logged In Users
- Internal Users: All Dream11 Employees
Further, users have the power to put more advanced configurations on the cohort with the help of the Include/Exclude functionality.
User Variant Assignment
Most of the use-cases, whether frontend or backend, require a real-time assignment of the user to an experiment. Through this, a user becomes a part of an experiment cohort only if they open the application.
Having said that, DRS provides support for the pre-assignment of users to an experiment for use-cases where batch processing is involved. This is for experiments like testing the validity of machine learning models, personalisation and recommendation algorithms, pre-computed promotions strategies, and mast-blast communications.
External Integrations
One of the major charters for us while building DRS was to make it in a highly modular manner so that various blocks can have a plug-and-play functionality of their own. Hence, DRS obliges if one customer wants to use their own user-experiment assignment logic.
Thus, a wide variety of sampling scenarios are possible through DRS.
Sampling Techniques
Cluster
User population is first divided into groupings or clusters via some clustering algorithm or ML model. Then, a cluster is selected in its entirety based on assignment strategy and attributed to the variant as per the specified allocation. At the end, all users belonging to a cluster will only get mapped to one of the variants.
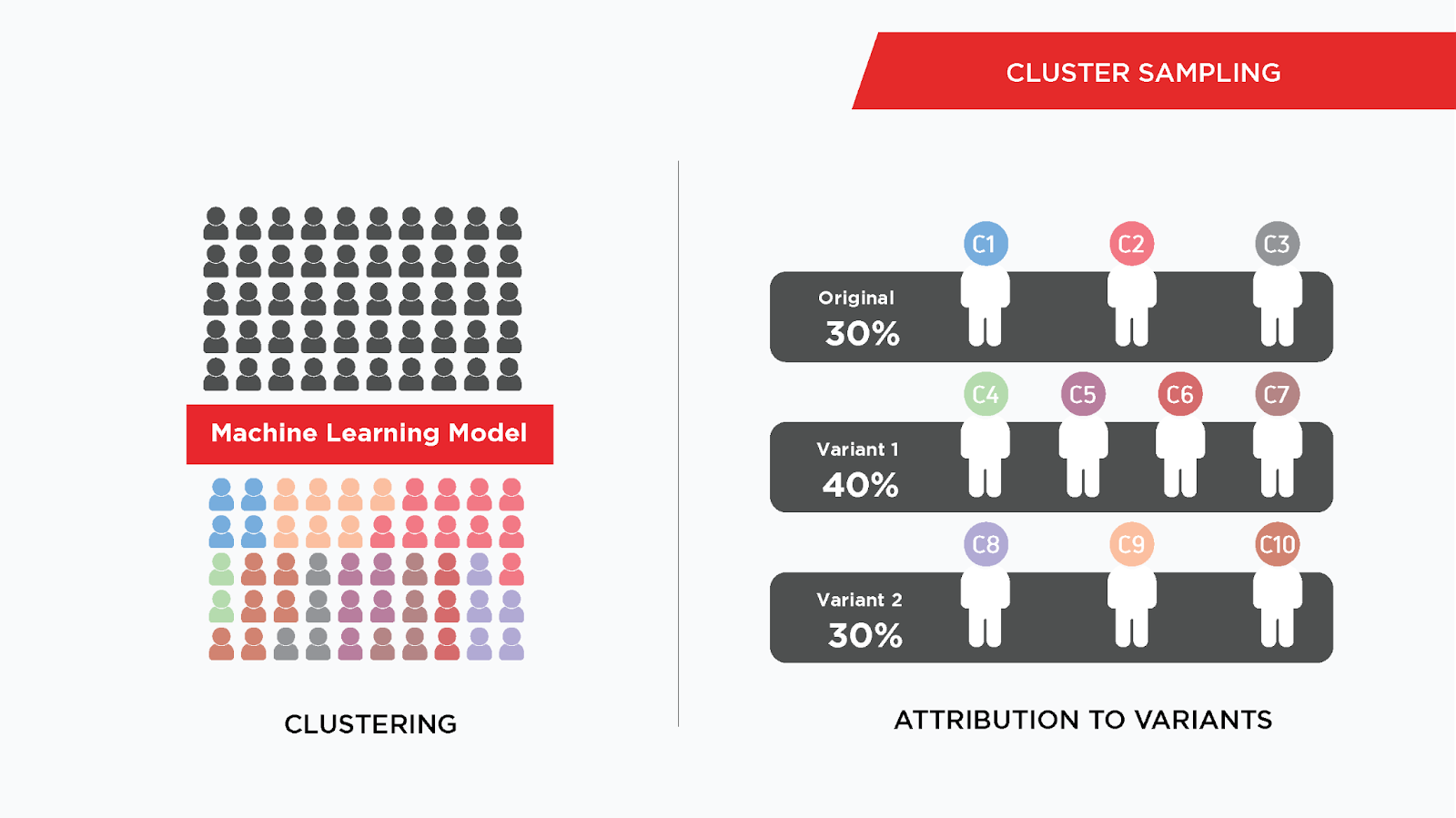
Manual Mapping
There are experiments where mapping of these clusters has to be precise. Then, clusters are manually mapped to variants as defined by the user.
Stratified
User population is first split into various mutually exclusive, homogeneous and non-overlapping strata. Users with similar affinity define a stratum. Let's say you want to use 10 user properties and 5 computed attributes of the user for identifying strata. Each unique combination of the above 15 traits will become a stratum. Then the sample is drawn according to an assignment strategy from each stratum to be attributed to variants as per defined ratios.
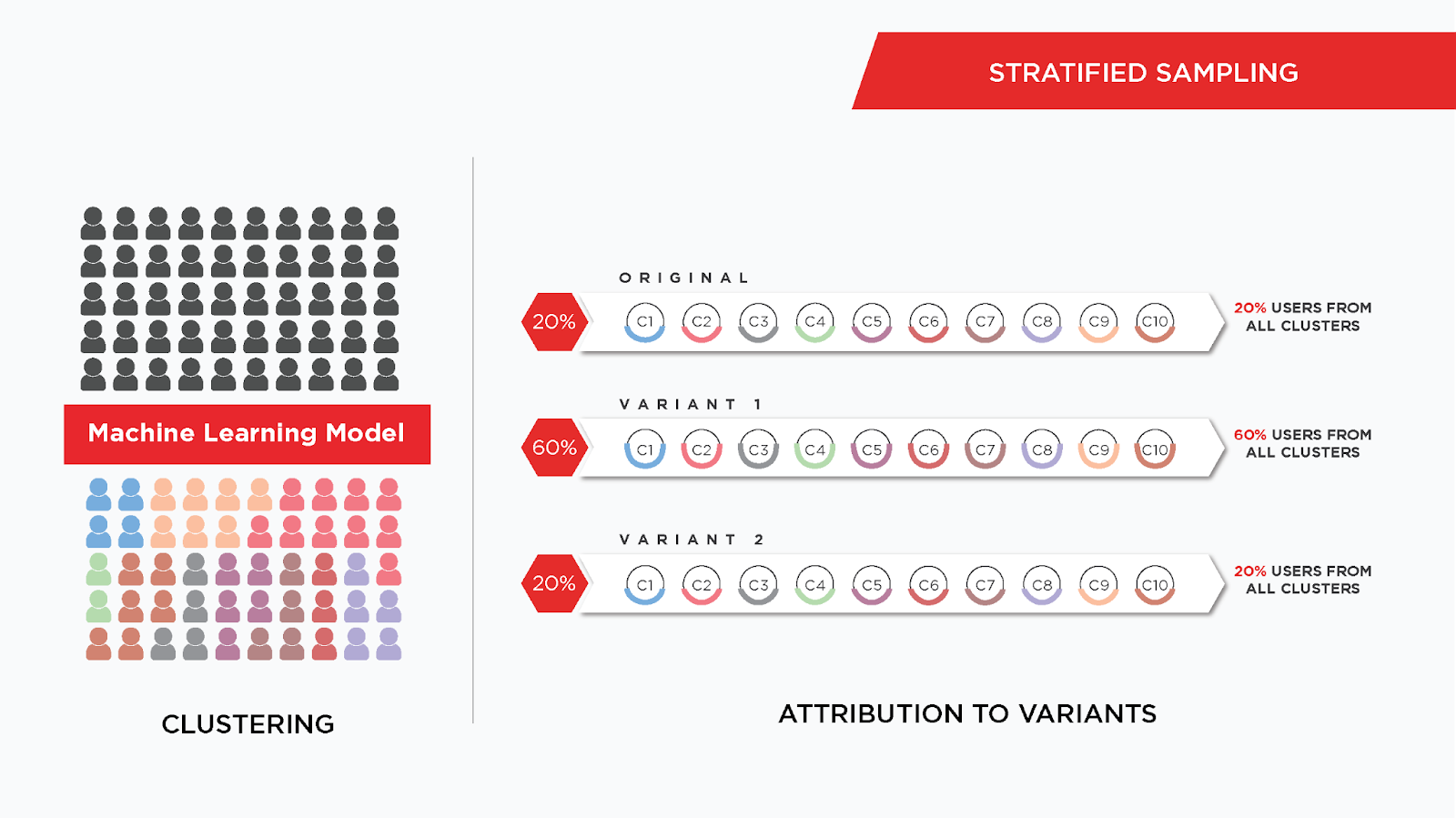
Assignment Strategies
Randomised
A user gets assigned one of the experiment variants selected in a random fashion weighted by the allocation percentages of variants. Even though this is a reliable strategy for most assignments, in case of cluster sampling, this can produce skewed assignments due to non-uniformity in cluster sizes.
Round Robin
The variants allotted to a user are rotated for each request based on their percentages. We maintain an overshoot map that denotes how much the current allocation of a variant exceeds the intended allocation. We try to reduce this by allotting the variant that has least overshoot value. This value is stored in a local cache, in order to handle the large amount of requests. And this value is periodically synced with a database to maintain balance across the application servers
Isolation amongst experiments
Experiments produce data! The concern though is if we can have confidence in the data produced through the experiment. Is it reliable?
For the data to be reliable, it has to be guarded and kept isolated from external factors that can have a bearing on the data metrics. The isolation should be based on two key factors:
Users
We need to maintain exclusivity of the users being marked to a particular experiment. In simpler terms, the users assigned to one experiment should not be assigned to any other experiment.
Slow-release with traffic exposure
With hundreds of experiments running in parallel, it's paramount to have a non-buggy user experience. DRS allows us to control the exposure of the traffic so as to spread out the impact of the experiment over a period of time. In case of any issues with the experiment, the impact is minimised. We can use our exposure field to control user traffic that will be exposed to the given experiment. On cautiously assessing things, we gradually increase exposure to 100%.
Our source of inspiration for this was the canary deployment process where user traffic is gradually moved to a newly deployed stack.
Ensuring Threshold
Threshold is configured for an experiment to maintain a check on the maximum number of users it can be exposed to. As there can be millions of users in a cohort, if we want to expose this experiment to a limited number of users, we can use threshold. This is especially crucial in exclusive experiments as they hoard up an unnecessarily large number of users. As millions of requests per minute are served, simply updating the count would create a hotkey problem. Given the business, confirm if the threshold is used to ensure users are not over-allocated to few experiments.
Tech@Dream11
Challenges
The traffic on Dream11 during big-ticket events can go from thousands of concurrent users to millions in just a few minutes and our edge services handle over 120 million requests per minute (RPM) during peak load.
We had the challenge of designing a highly tunable experimentation system that can scale at ultra-low latency. Before serving experiments we had to address these key problems:
- Segregating relevant requests, such that the experimentation service does not deal with such high RPM
- Experiments are relatively long-running and user to variant stickiness is maintained throughout an experiment's lifetime
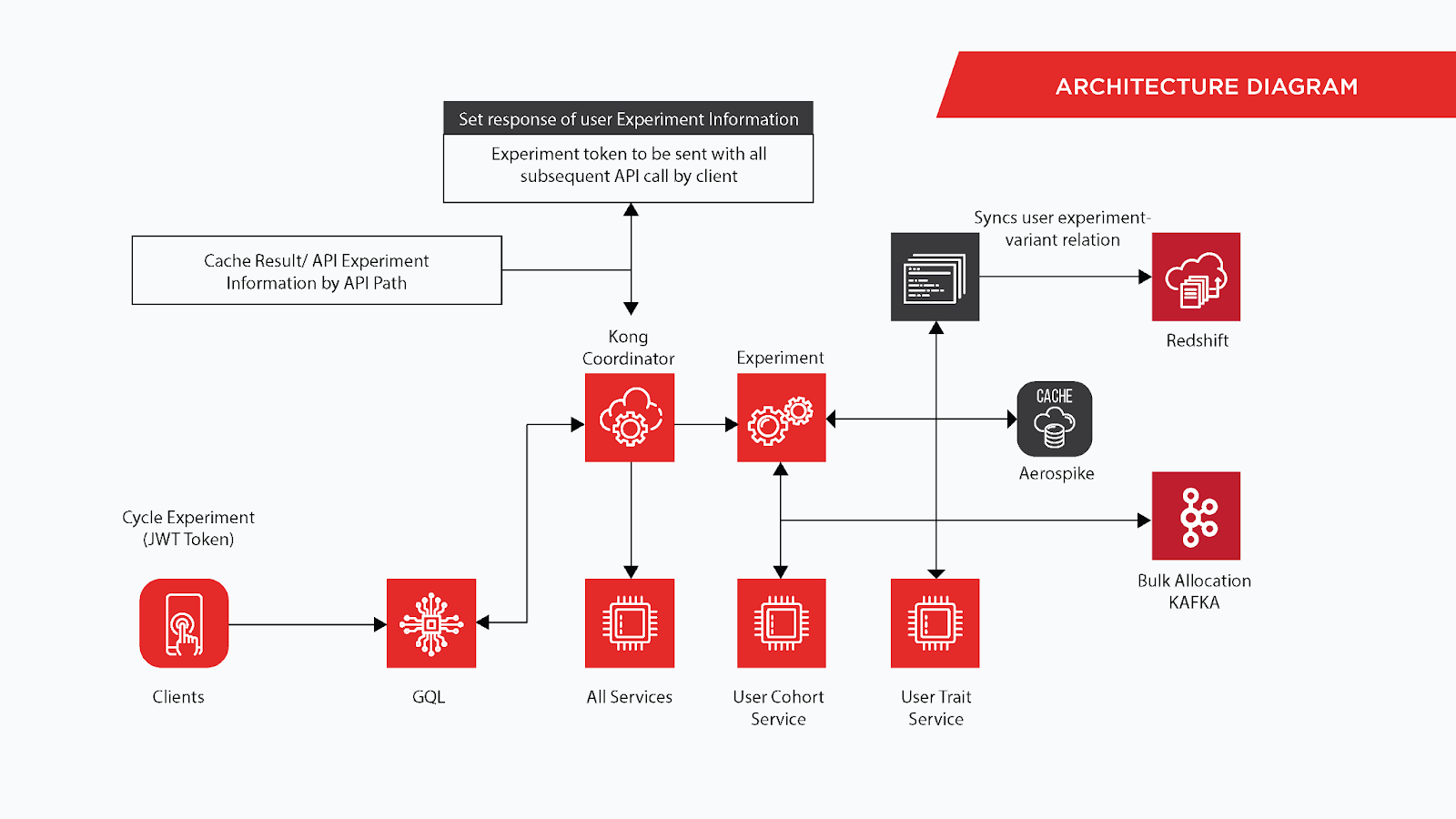
Implementation Details
- As specified earlier, experiments are served to users in two modes:
- Frontend
- Backend
- Experiments are configured on unique paths. These unique paths are the page names for the frontend and API paths for the backend.
- The frontend experiments are driven by API requests from clients on page load/app launch. For frontend assignments, multiple paths are requested in one request at app launch.
- For backend experiments, the experiment information is injected in the API request header.
- DRS responds back with the variant information each user is assigned. It's now a responsibility of the frontend client or the backend microservice to interpret those config variables based on their unique business logic.
Optimizations
Managing Traffic
We introduced tokens and added a heuristic at the API gateway layer using an Experiment SDK. The token contains experiment mapping and is circulated with each request which is inspected at API gateway and forwarded to experiment service only if users are eligible for a new assignment.
Managing Data
The experiment service uses Cassandra (a free and open-source, distributed, wide-column store) as the source of truth and Aerospike (a flash memory and in-memory open source) as its cache. We ensure that the system scales linearly with the ever-growing experimentation adaptation, and the data is synced with Amazon Redshift (a data warehouse) to be used for all analytical processes.
All data is denormalized to have pointed queries. Some data that is updated infrequently is also kept in the local cache and is periodically updated in background. This also guards us against the thundering herd problem.
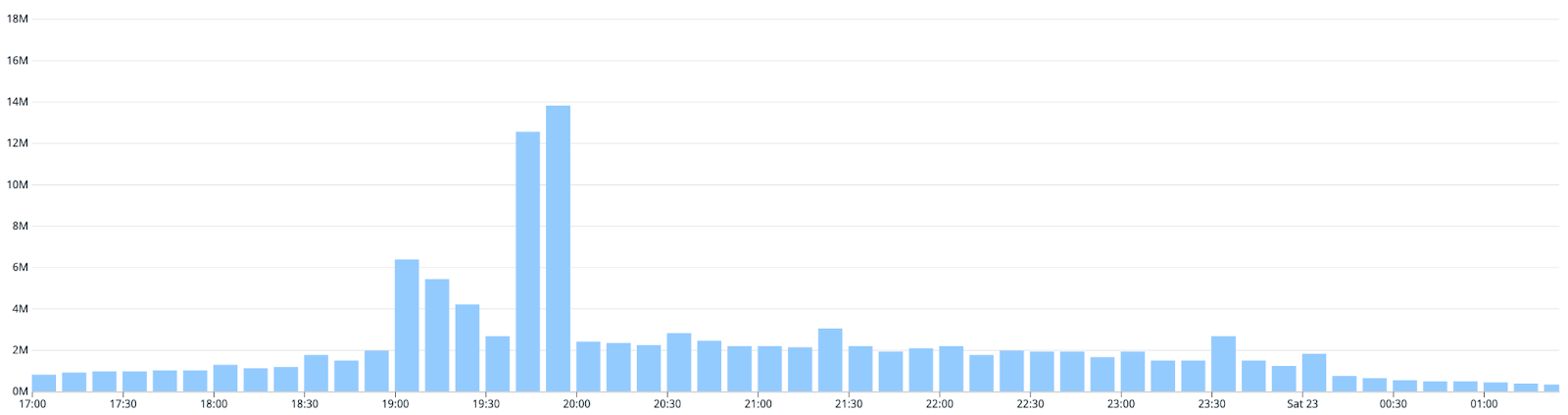
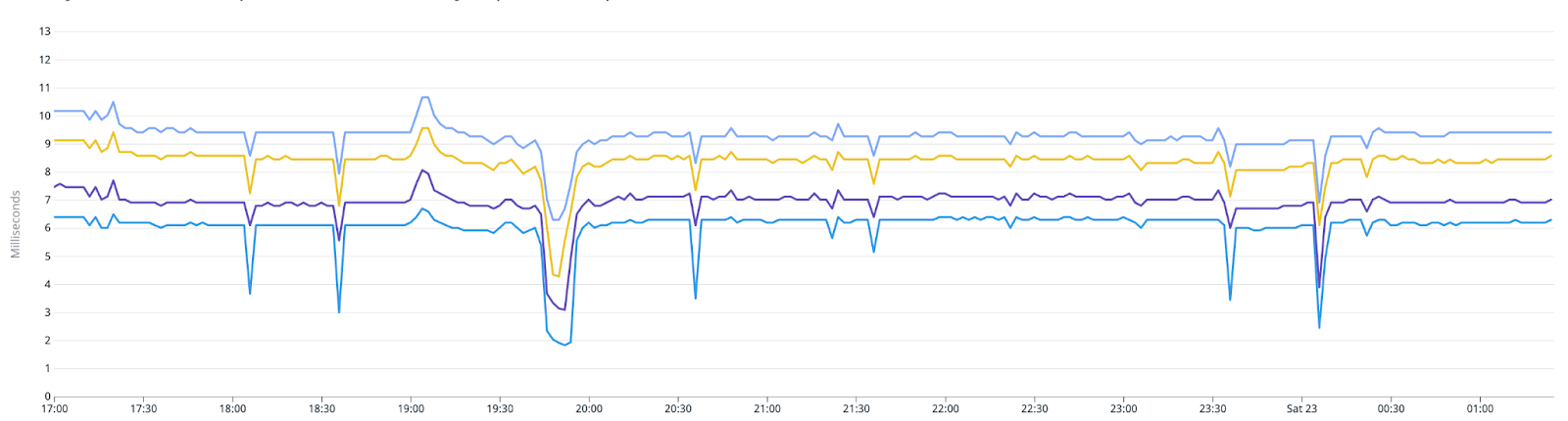
Performance Numbers
We receive bursts in our traffic just before a match starts, with this effect getting exaggerated during the IPL. Our experiment service has been able to serve a peak load of 16M requests with an API latency of p95 < 10ms.
The below graph shows the spiky request patterns that the experimentation service handles with best-in-class performance:
Future of DRS
At Dream11, we have just begun our journey in the world of experimentation with DRS and there is a long way to go. Here are some significant milestones that we have envisioned for the immediate future:
Augmented Analytics
Tracking of primary and secondary metrics for experiments, totally integrated with DRS and real-time!
Bandit Testing
Intelligently auto-scaling the attribution of variants to a cohort to finally make the best performing variant the default version.
No-code Experimentation
A low-code, no-code capability for non-technical stakeholders to create UI-driven experiments.
Remote Config
Providing visibility and fine-grained control over app's behaviour and appearance so one can make changes by simply updating configurations in DRS, and easily turn feature exposure on and off.
Are you interested in solving problems related to data at multi-petabytes’ scale, handling and processing billions of data points per day or working with passionate and innovative minds on the turf? We are currently hiring across all levels! Apply here to join us. More exciting stuff to come from the Experimentation Team at Dream11. Stay tuned!



