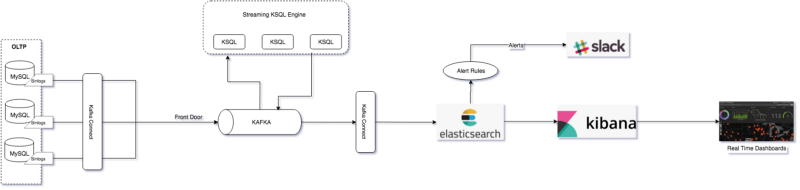
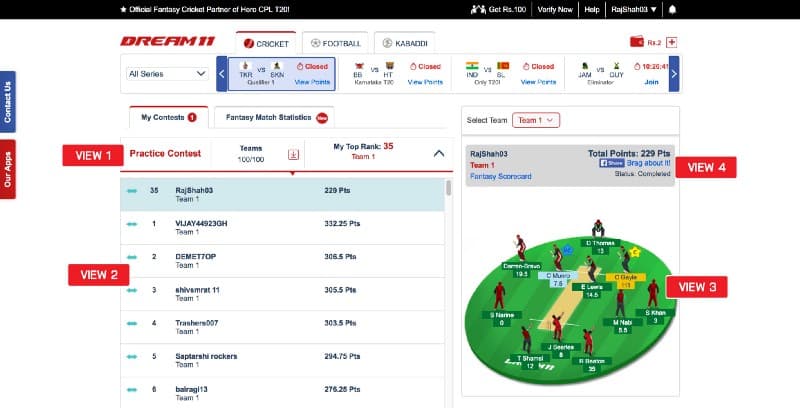
The blog covers the importance of real-time data processing in gaining a competitive advantage in various industries. It introduces Streamverse, Dream11's in-house real-time data processing platform and its core primitives: Streams and Operators, and provides a detailed overview of the platform's architecture. It also gives examples of how real-time data processing can improve user engagement, personalisation and real-time analytics, empowering a product to take business critical decisions.
- Published on