

Building Scalable Real Time Analytics, Alerting and Anomaly Detection Architecture at Dream11
- Published on
Introduction
Building batch data analytics platform traditionally is not a new trend. While the industry is moving towards agile and shorter development cycles, scope of building data platform is no more limited to batch processing. Businesses aim for real time updates on-the-go. No one wants to know something that has broken after an hour.
Many of us must have seen an application use RDBMS OLTP directly and run SQL statements to do all these. In case you are wondering- is this a good solution? The answer is- it depends.
Using OLTP transactional systems to run your real time analytics might be enough for your use case. However as project requirements grow and more advanced features are needed — for example, enabling synonyms, joint analytics or doing lookups — your relational database might not be enough.
Our journey at Dream11 was no different. It started with fulfilling requirements from traditional way and as complexity started biting us in terms of volume and latency, we moved to more powerful, distributed real-time engines.
Data volume at Dream11
- Deals with 3+ TB of data per day
- 10M+ transactions per day
- 2.8 M concurrent users
- Billions of clickstream events per day
Why Dream11 decided to implement real-time pipeline
At the core of Dream11 Engineering, we use AWS Aurora as an OLTP system. These systems are very efficient for OLTP load but are not meant for OLAP kind of workload. We can’t perform aggregation or OLAP type of queries on these transactional systems.
To solve the above problem obvious solution is to run your OLAP queries on your data warehouse. In our case, it was AWS Redshift. We have ETL pipelines in place to load data from transactional system to our warehouse. These ETL pipelines run every hour thus real-time analytics is not possible on warehouse
What we wanted to achieve
We wanted to perform real-time analytics on the data, which is residing in the transactional system, in our case AWS Aurora database.
Some of the use cases are as follow: -
- Know the real-time rate of contest joins
- Know the real-time aggregated status of payment gateways
- Identify real-time anomalies eg: PG going down, unusual traffic on the system
- Realtime aggregated view of outcome of marketing campaigns
- How customers are using discount coupons once promotion goes live
- Realtime alerting once Mega contest is above 90%
Architecture overview
So, let’s explore How Dream11 has implemented the pipeline. To understand the architecture better, we will divide the pipeline into various stages -
- Pull data from various transaction systems on a common bus in real-time
- Perform data enrichment
- Push data into a real-time data store for a real-time analytics. This allows data visualization, rule-based anomaly detection and alerting
- Operations & Monitoring

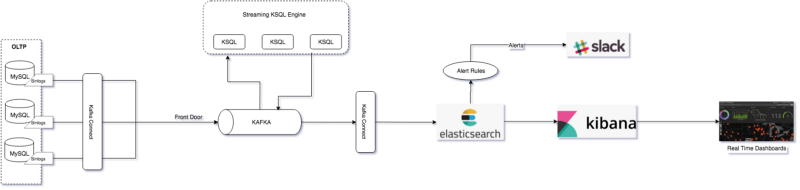
Moving data into Apache Kafka with the Kafka Connect
We have used Kafka connect to pull data from our transactional system to Kafka. For this, we have primarily used Debezium & JDBC source.
Kafka Connect, an open source component of Kafka, is a framework for connecting Kafka with external systems such as databases, key-value stores, search indexes, and file systems. Using Kafka Connect, you can use existing connector implementations for common data sources and sinks to move data into and out of Kafka. Kafka Connect is focused on streaming data to and from Kafka, making it simpler for you to write high quality, reliable, and high-performance connector plugins. It also enables the framework to make guarantees that are difficult to achieve using other frameworks. Kafka Connect is an integral component of an ETL pipeline when combined with Kafka and a stream processing framework. Kafka Connect can run either as a standalone process for running jobs on a single machine (e.g., log collection), or as a distributed, scalable, fault tolerant service supporting an entire organisation. This allows it to scale down to development, testing, and small production deployments with a low barrier to entry and low operational overhead, and to scale up to support a large organisation’s data pipeline.
Source Connector
A source connector ingests entire databases and streams table updates to Kafka topics. It can also collect metrics from all your application servers into Kafka topics, making the data available for stream processing with low latency.
Sink Connector
A sink connector delivers data from Kafka topics into secondary indexes such as Elastic search or batch systems such as Hadoop for offline analysis.
The main benefits of using Kafka Connect are:
Data Centric Pipeline — use meaningful data abstractions to pull or push data to Kafka.
Flexibility and Scalability — run with streaming and batch-oriented systems on a single node or scaled to an organization-wide service.
Reusability and Extensibility — leverage existing connectors or extend them to tailor to your needs and lower time to production.
Debezium is an open source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases. Debezium is durable and fast, so your apps can respond quickly and never miss an event, even when things go wrong.
The JDBC source connector allows you to import data from any relational database with a JDBC driver into Apache Kafka topics. By using JDBC, this connector can support a wide variety of databases without requiring custom code for each one. Data is loaded by periodically executing a SQL query and creating an output record for each row in the result set. The database is monitored for new or deleted tables and adapts automatically. When copying data from a table, the connector can load only new or modified rows by specifying which columns should be used to detect new or modified data.
Learnings:
- Debezium works on Binlog, it adds overhead on the database which will eventually impact the performance of the database.
- JDBC source cannot detect deletes and intermediate updates.
- JDBC can miss long running transactions
Enriching datasets with KSQL
Confluent KSQL is the streaming SQL engine that enables real-time data processing against Apache Kafka It provides an easy-to-use, yet powerful interactive SQL interface for stream processing on Kafka, without the need to write code in a programming language such as Java or Python. KSQL is scalable, elastic, fault-tolerant, and it supports a wide range of streaming operations, including data filtering, transformations, aggregations, joins, windowing, and sessionization.
We have used KSQL for various use cases mainly Stream join, Data enrichment, Filtering, Aggregation
Learnings:
1) Although KSQL is a very powerful tool it is in early stages. We have observed some data loss issue.
2) KSQL file mode deployment is preferred over CLI mode. CLI mode some time causes duplicate records issue
Indexing documents with Elastic Search Connector
The Elasticsearch connector allows moving data from Apache Kafka to Elasticsearch. It writes data from a topic in Kafka to an index in Elasticsearch and all data for a topic have the same type.
Learnings:
- We have created weekly indexes in Elasticsearch for easy archival of older data. We can use topic index map property to create weekly indices
- Supports upsert/append mode
- Schema mappings needs to be handled properly
Setting up Alert rules for anomaly detections and real time dashboards
ElastAlert is a simple framework for alerting on anomalies, spikes, or other patterns of interest from data in Elasticsearch
Several rule types with common monitoring paradigms are included with ElastAlert:
Match where there are at least X events in Y time” (frequency type)
Match when the rate of events increases or decreases” (spike type)
Match when there are less than X events in Y time” (flatline type)
Match when a certain field matches a blacklist/whitelist” (blacklist and whitelist type)
Match on any event matching a given filter” (any type)
Match when a field has two different values within some time” (change type)
Match when a never before seen term appears in a field” (new term type)
Match when the number of unique values for a field is above or below a threshold (cardinality type)
Latency Monitoring:
IPL is our peak time. During this time, we have observed end to end maximum latency of less than 2 minutes. New Relic monitoring dashboards in place with required alerts with thresholds in place for attention if something goes wrong with pipeline
Wrapping it up
With this architecture we were able to achieve ingestion rate of ~40k events/sec with an end to end latency of < 50 secs. This has helped our operational team take real time decisions on adding more contests if required. Product team is using this to know current inflow, user activities and decide on strategy on giving promotions and making user journey’s more interactive. Marketing team is using this to know their campaign effectiveness in real time and make adjustments on the fly.
What’s next? Data Highway
We would be sharing our journey of implementing clickstream real time event processing in-house framework at large scale. That’s Data Highway. Stay tuned :)



