

Building DataAware: The In-House Funnel Analytics Tool At Dream11
- Published on
Introduction
As the world’s largest fantasy sports platform with 110 million+ users, Dream11 hosts hundreds and thousands of fantasy sports contests every day. Here, our users can actively engage with real-life sporting events and showcase their knowledge of sports. However, enabling so many users to have the best experience possible on Dream11 every day can seem challenging. At such a large scale, one of the common behavioural analytics requirements that we have is Funnel Analytics, to understand user behaviour and preferences. With our in-house Data Platform where we collect, process and serve terabytes of data per day, we have solved this easily. And in this journey, our hero has been DataAware — a Funnel Analytics tool that we use to recognise and know user behaviour trends at such a large scale as Dream11. We developed DataAware with the following features:
- Ability to provide a user interface to select the event sequence interactively
- Ability to apply filters on event properties
- Auto-suggestions on events filter properties
- Define conversion window
- Date Range — the ability for users to analyze across days, weeks, or months
Defining the Funnel and its importance for Dream11
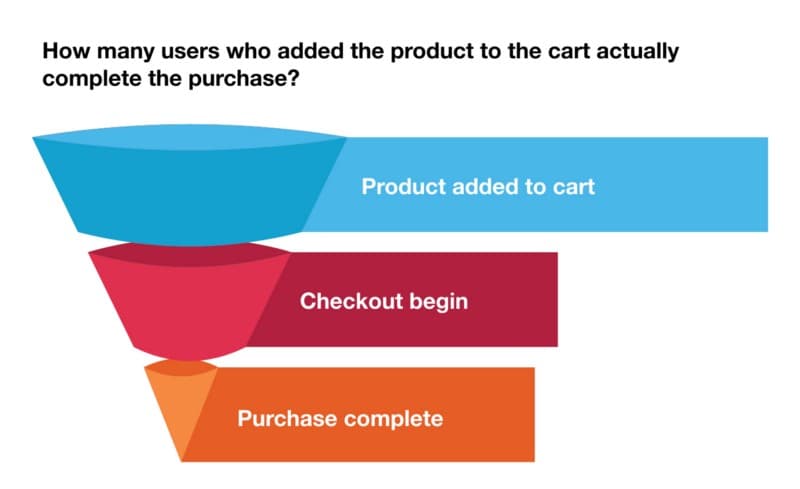
Funnel analysis involves mapping and analyzing a series of events that lead towards a defined goal, journeys like an application opened to join contests, understanding drop-offs in navigating through app and taking appropriate actions to increase conversions in Dream11, or the flow that starts with user engagement in a mobile app and ends in a sale on an eCommerce platform. Funnel analysis is an effective way to calculate conversion rates on specific user behaviours. This can be in the form of a sale, registration, or other intended action from an audience.
Below is a common example of e-commerce funnel analysis:

Architecture of DataAware


Data Collection — Raw Layer
We have Data Highway in-house events collection service to collect events from mobile devices and websites. Data Highway captures a stream of events in the JSON format on Kafka topics. To make this data queryable, we have to park this data somewhere. We choose S3 as our data lake and Confluent S3 sink connector to sink events data on S3. At this moment, we have plain text JSON data on S3 as follows.


Key observations:
- Every event lands into a separate Kafka topic, subsequently to separate S3 directory and schema registered in centralized Glue catalog — so that it is queryable via any query engine
- Every event data is partitioned by date (Hive-style data partitioning) to reduce data scan during daily ETL jobs
- The raw layer is being used for near-real queries and has strict data retention policies. Raw layer data gets moved in a more efficient and optimized processed layer.
Data Storage and Processing
The processed layer takes care of data enrichments, lookups, denormalization and storage of data in a more efficient Parquet format.
Benefits of the Parquet format:
- Requires minimum data scan due to columnar format, resulting in cost-saving since Athena costs per terabyte data scan by underlying Athena query
- Is efficient for aggregation queries like funnels analytics
- It supports flexible compression options and efficient encoding schemes
- Apache Parquet works best with interactive and serverless technologies like AWS Athena


Query Layer
For the query layer, we had two choices — serverless Athena and in-house presto cluster that we have been using for our batch processing, for more predictive response time.
Athena
Athena is an interactive, serverless query engine with a pay-per-use model based on per TB data scan. It works best on top of parquet and is efficient in data partitioning. However, in certain cases and large data scans, the performance could be unpredictable based on time of the day and the shared pool of resources available behind the scenes, as its managed service.
Presto
Presto gives full-control over performance and predictable response times, for us having a centralised glue catalog which is available with any query engine — Spark SQL, Presto, and Athena. We use our smart query engine to be picked up dynamically based on data scan and query performance patterns for queries.
API Layer — Dynamic Query Generation
The Application Programming Interface (API) layer is backed by flask framework, with multiple micro services to power the different UI components such as:
- The initial listing of events for end-user based on event selection
- Fetching the list of event attributes to apply filters, and while applying filters
- Identifying the possible values for event properties and giving auto-suggestions to the end-user.
This is done behind the scenes to keep all the event metadata up to date. We have real-time jobs interacting with real-time layers to keep this meta-information live.
Based on user inputs, and with a standardized glue catalog for every event, we form the funnel queries on the fly and send them to the query engine for getting those aggregated conversion numbers. We then send the result back to the visualization layer. Also, we have a caching layer in between to cache the results. If a similar query hits the service, the comparison is made based on entire query semantics such as participating events in the funnel, filters, and date ranges. The result will be the same and it directly gets served from the cache.
Visualization Layer
Considering niche requirements that were not satisfied by leading BI tools, we decided to build our custom UI with UX tailored to our requirements. We already had an internal portal to manage internal systems, and we plugged in one more component — DataAware. We had written it from scratch using React, by leveraging various community charting libraries. The React PWA (Progressive Web App) gives various functionalities to the users, like auto-suggesting values to users. We also developed capabilities to share and save the funnels for agile accessibility. All of these UI components were powered by the above-mentioned APIs written in Flask.
All in all, building our own in-house funnel analytics tool was a resounding success and helped bridge all the gaps that were previously missing in our pre-existing analytics tool. Here’s to DataAware!
Keen to work with us and build unique solutions at Dream11? Join us by applying here!
- Authors

- Name
- Dream11
- @Dream11Engg


