

How does Dream11 serve millions of Personalised Contests in a match
- Published on
At a time when we are collectively homebound, thanks to the pandemic, the Dream11 Indian Premier League (IPL) 2020 came like a breath of fresh air for cricket fans everywhere. Not only did the Dream11 IPL 2020 fill an otherwise gaping void in the realm of sports this year, but it also kept our passion for cricket, a thread that binds us together, burning as brightly as ever.
Besides watching the matches, sports fans participated in exciting fantasy sports contests on the Dream11 app and showcased their skill and knowledge of the sport! Fans can create their own team of real-life players from upcoming matches, score points based on their on-field performance and compete with other fans. What’s more, as Title Sponsors of the Dream11 IPL, we were committed to providing fans with a secure and seamless experience.
Different types of contests allow users to compete and win big, thereby increasing their engagement. Creating customised or personalised contests are a prime component for best user experience. With hundreds of highly personalised contests running on the platform simultaneously, meeting every user’s requirements, it is inevitable to encounter several challenges during the entire process. To keep these contests running smoothly, we play an entirely different ball game at the backend. So what are these, and how do we manage to address each of them?
Business Requirements for Creating Personalized Contests for Users
Contests are the centre of attraction for every user, which motivates us to manifest contests without any hiccups and ensure a smooth-sailing experience. For that, we need to meet a set of business requirements that will enable us to do exactly this. Each contest is different from the others in terms of variables like prize money, contest entry amount, number of winners and total participants. To pique our users’ interest and provide contest options best suited for them, the contest page is divided into Sections like ‘Mega Contests,’ ‘Head to Head Contests,’ ‘Contest for Champions,’ and ‘Top Picks For You,’ to name a few.
Several events are generated every minute as users interact with the application. We wanted to leverage the data collected from these events to create User Cohorts. A user cohort is a logical grouping of users based on their activity, playing pattern and history.
For receiving a maximum response, we apply target campaigns to compartmentalise users and serve relevant contest sections to them based on their cohorts. These cohorts keep changing in real-time basis user activity and events. Cohorts are mapped to relevant Contest Sections thus allowing users to see exclusive sections.
The Product and Data team at Dream11 leverage the following features too:
- Personalise contests based on user attributes
- Rules based exclusive contests
- Run A/B tests on contests and sections to figure out which variant works the best
How we maintain user-cohorts
Self serve admin panel is provided to write/maintain rules to create cohorts and map relevant contest sections to that cohort.

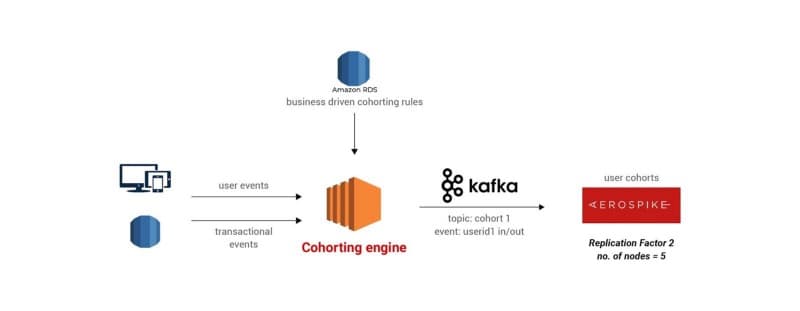
Once the cohort is activated, a query to data-lake is fired to bootstrap users who pass the cohort rules into the cohorting engine. Then this data is streamed to kafka as cohort_in event to be consumed by user-cohort service.
The users keep falling in and out of the cohorts based on real-time events as being processed by the cohorting engine.
How we serve fast-filling contests at Dream11 Scale
In a typical IPL match, there is a lot of incoming traffic. Once the contests are filled to their optimum capacity, they are dynamically replaced from backend with new contests in real time to keep the inventory refreshed.
After the toss of every match, we typically see a high surge in contest joins per second. This leads to a high rate of contests creation, adding upto millions of contests in a single match.
The starting point is contest creation which is done by our AI based Contest Generation Engine (CGE). CGE calls Contest-Generation service which generates different kinds of contests in contest datastore i.e. VoltDB.
From there, we stream these generated contests to Spark Streaming where it continuously writes new contests to our contest cache store Aerospike and expires the filled contests. This needs to be done in real-time as users need to see updated contest data.
We chose Aerospike since it is a distributed, scalable database with intelligent re-balancing and data migration. But like any other distributed system it has Eventual Consistency to compensate for High Availability which leads to another important problem to be solved:


Hot-key scenario: As so many users are playing together, our typical user concurrency is around 5 million post-toss. Since everyone is trying to play the same match, they will see a similar list of contests. Clients need to reflect the number of spots left at sub-second level. Serving 5M users from a single aerospike node is impossible as it will create a HOT-KEY. So, we need to replicate this data to other nodes and read from Master and Slaves both.
Eventual consistency trust issue: If we replicate (replication factor >= 10) then eventual consistency may cause users to see the ‘Number of spots left’ increasing (different data because of eventual consistency between nodes) which can lead to big trust issues among users. The number of spots can either decrease or remain constant. Under no circumstances should they increase.
Solution:
We started doing key seeding for all active contests in aerospike while keeping the replication factor of each key as 2. Key seeding basically means creating multiple copies of the same data and writing it to cache. We configured our spark streaming to write 10 duplicate copies of match_contests key by appending _1, _2,…,_10 to the keys and hashed each userId so a particular user will always read from a particular copy. This made sure that a user always sees ‘Number of spots left’ as strictly decreasing even if spark fails to write a few copies.
int keySeed = userId % (no. of copies); Map contestData = getFromAerospike(‘match_contests_’ + keySeed);

Request response cycle: On landing on the contests page, for each user a request is made to contest microservice which does the following:
- Get user’s cohorts from user-cohorts microservice.
- Prepare a list of contest sections based on the user’s cohorts.
- Read filtered contest sections from aerospike to get active contests.
- Asks promotions microservice for any running promotions.
- Sends back the response.

This system has been a great success to generate contests and give a personalised touch to them through cohorting. At Dream11, we vouch for the quality and output of work to make fantasy sports an unforgettable experience for users.
Interested in building similar systems for serving 100M & growing users, reach out to us here.



