

Data Beam: Self Serve Data Pipelines at Dream Sports
- Published on
Introduction
As the world’s largest fantasy sports platform with 160 million+ users, Dream Sports hosts hundreds and thousands of fantasy sports contests every day. At this scale, data is not only fast-growing, but also distributed in different forms. In order to have informed decision making throughout the company, it is necessary to bring together data from isolated OLTP systems.
From day one, we have been on a journey of solutions for data replication from source to destination. In this blog, we intend to share our current setup for transactional pipelines and journey of automating transactional data pipelines setup.
Why did we build Data Beam?
Data pipelines are key for any data lake and warehouse solutions. Our transactional data analytics started with MySQL, Kafka Connect, Redshift and Looker. Most data engineers (DE) in the industry find themselves engaged in manually setting up these data pipelines.
We had a similar start of our journey,
- Requirement coming to DE for data pipeline
- Understand data and its nuances
- Setting up source JDBC connector with custom configs based on data type, PII
- Setup S3 sink connectors
- Manually create redshift table with custom data type mapping
- Plugging in deduplication logic in redshift load script
All this would consume time and also leave the scope for human errors. Furthermore, due to limited scope of process standardization, there were always new surprises coming our way, be it Incompatible data types, failing connectors, lack of quality checks and more. Maintenance overhead kept on increasing with time. Lack of observability and track of data quality was a constant concern with such manually managed data pipelines.
What is Data Beam?
At Dream Sports, we believe in enabling our teams with self-serve data products. This is where Data Beam was born. An integration platform for creating pipelines from various sources to destinations with minimum effort.
It comes integrated with a quality check module that tells the health of these transactional data pipelines by periodic count checks. All of this combined with a sophisticated UI increasing observability and ease of use.
How does Data Beam work at Dream Sports?

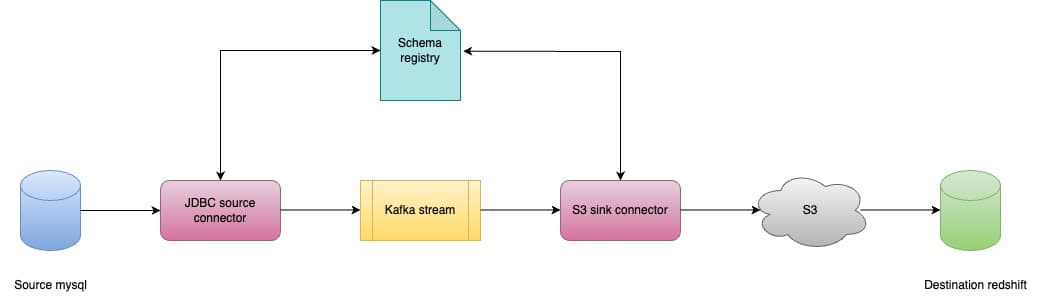
Components
JDBC source connector : We use a query-based change data capture approach based on a timestamp field and an incrementing identifier column. An optimally designed poll interval to meet the SLA without putting too much load on the source system is ideal for analytical use cases.
Schema registry : A standalone schema registry server is used to maintain the schema of all topics in the kafka cluster and make it available for the producers to check if the incoming message matches the compatibility rules of that topic. This acts as a protective layer from sending incompatible messages straight down to our destination, and also as alerting for any schema evolution that needs to be propagated.
Kafka stream : Kafka is one of the go-to message queues when you are dealing with streaming data, but it also acts as a great ingestion tool for analytics use cases dealing with transactional data. It gives flexibility to use various source sink configurations using Kafka Connect and its pre-built connectors. A messaging queue between source and destination helps decouple the two processes that can then be tuned based on the load bearing capacity of individual data stores.
S3 sink connector : Once data is available in kafka, it needs to be migrated to a permanent storage based on retention configurations on kafka. Confluent connects s3 sink is ideal for periodic flush to s3 data lake. Flush can be tuned based on the number of records or a time window. These configurations are super useful when data volumes vary among source tables.
S3 : In Dream Sports data platform ecosystem we use S3 as our data lake where all transactional data resides as a permanent copy.
Redshift : Redshift is our warehouse which is used for building analytics dashboards and ETLs.
Architecture diagram


Components
Data Beam UI and Web server
Data Beam UI backed by a web server is the entry point for users who want to set up a data pipeline from source RDS to Redshift. User provides source and destination details along with few configuration details like unique key, time stamp column for final deduplication at the destination.
Once a pipeline is submitted, the user can view pipeline status. Users also receive slack notification once the pipeline is deployed and data starts flowing.
Airflow
Complete setup orchestration for all types of pipelines is maintained by airflow. At the submit of a new request, a DAG is triggered via airflow API that initiates the process.
This DAG acknowledges the request and selects setup DAG based on the type of pipeline requested. Multi instantiation of setup DAG, one for each pipeline, is done using a custom airflow operator. At the end, airflow sends success or failure notification to the user and data team.
All our pipelines and setup process is isolated, i.e. it's independent of the others so that no pipeline would impact the load of any other table. As we deal with a huge number of tables, we do not wait for the whole data load but auto monitor 2% data load into Redshift to alert users via slackbot that data flow has started.
QC
An inbuilt QC framework runs for all configured pipelines. The framework is smart enough to calculate a different sliding window for each table based on their load schedule and product SLA. Hourly count-check runs between source and destination to identify mismatch if any.
A QC ledger is maintained for all checks and a mismatch queue is updated for all failed checks. All records from the mismatch queue are picked twice by retry QC which runs every 4 hours. The framework maintains overall QC health status for each pipeline that is visible to the users on databeam UI.
Future Enhancements
- Auto healing capability on QC failures
- More sources and destinations like
- Mysql to Mysql
- Mysql to Iceberg
Reference Links




- Authors

- Name
- Dream11
- @Dream11Engg


