

Lessons learned from running GraphQL at scale
- Published on
At Dream11, we have experienced tremendous growth from just 300,000 users in 2015 to over 110 million users at present. To grow at this blazingly fast pace, we moved to a microservice architecture for developing backend systems.
As the number of microservices grew, it became increasingly difficult for frontend developers to fetch data from multiple services and present it on the UI (user interface). So, we decided to come up with a presentation layer that could provide us with:
- Network aggregation
- Data transformation
- Type safety
After due deliberation, we decided to use GraphQL

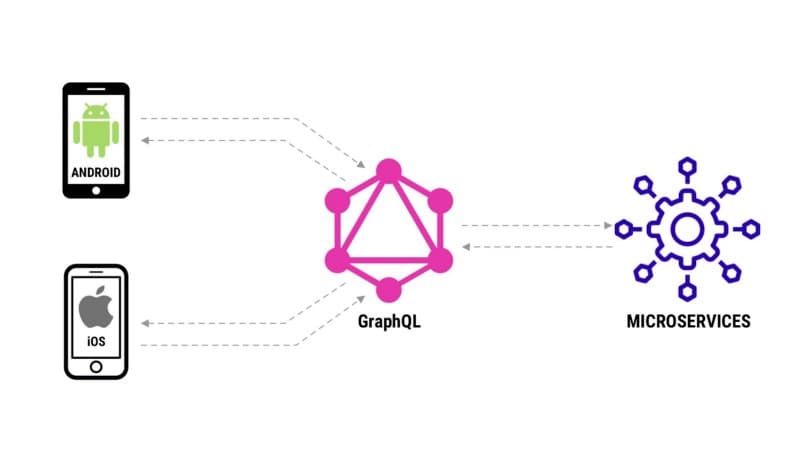
Brief History of GraphQL
Back in 2017 when GraphQL was just a buzzword and not many companies were using it at scale, at Dream11, we started using it in production. It was a simple expressJS based application that we deployed in front of our microservices based stack. We received positive feedback early on from our web teams and slowly moved our remaining clients — Android and iOS to GraphQL as well. At the same time, our active users were steeply rising. Our GraphQL usage doubled year on year.

Traffic Pattern


As seen in the graph above, there is a sudden burst of traffic during crucial events of a real match. During this time, traffic increases by almost 100% (e.g. 14 million to 28 million in 2 minutes at 20:00) in a matter of minutes. We use Amazon Web Services (AWS) at Dream11 and its components cannot auto-scale at this pace. So, we provision the load balancers and servers based on maximum predicted traffic. If you want to know more about how we do this, check this interesting blog that our SRE Dreamsters wrote on it.
Current Architecture

GraphQL servers are running on compute-optimised eight-core machines (c5.2xlarge). Each Elastic Compute Cloud (EC2) is managed by Auto Scaling Group (ASG). We provision approximately 7,500 instances for 1 million requests per second.
To route the traffic to these instances, we are using multiple load balancers. Keeping multiple load balancers solves two problems for us:
- A single load balancer can route traffic to only a limited number of instances.
- A single load balancer can become a single point of failure.
Owing to the spiky traffic pattern, we have to pre-warm the load balancers as per the predicted peak traffic.
Optimisations Done Over The Years
To accommodate this kind of hyper-growth and impulsive traffic patterns, the GraphQL service went through multiple optimisations over the years. We used multiple strategies to optimise resource utilisation. Few things that really stood out were:
1. Batching
In GraphQL, each resolver function only knows about its own parent object. If a case arises where two resolvers are making requests for the same data, in order to avoid it, we use Dataloader, which is a library to batch requests.


2. Caching
In order to reduce the load on graphQL servers, caching is done at two levels- one, on the graphQL servers, and two, on the clients.
- To enable caching, each backend Application Programming Interface (API) sends X-TTL headers with the response. GraphQL caches globally cacheable resources for a certain amount of time (TTL).
- During query evaluation, graphQL calculates the TTL for query response and sends it to clients. This enables clients to cache graphQL responses.
Impact On Downstream Services
GraphQL performs a lot of common operations for all microservices e.g. authentication, data manipulation for the presentation layer, data caching, etc. This allows microservices to be simple and decoupled from each other. Caching has reduced load on microservices and hence, we could aggressively downscale them.
Costly Abstraction
The Indian Premier League (IPL) is a celebrated sporting festival in the country and we see an enormous amount of activity on the Dream11 app. The League’s 2020 edition was special for us since Dream11 was the Title Sponsor. During the League, we received peak traffic of around 40 million requests per minute with a peak concurrency of over 5.5 million. In spite of performance optimisations being done year after year, we heavily relied on the increased capacity to provide 100% uptime, which resulted in very costly infrastructure.
The graph shows the cost of GraphQL servers during the IPL 2021 with respect to other microservices

For IPL 2021 we predicted almost double the traffic that we received in the previous edition(IPL 2020).
What were the main challenges?
While running GraphQL on production we faced two major challenges:
1. Unpredictable Performance
Previously there were random spikes in CPU (Central Processing Unit) and memory utilisation, owing to a number of reasons :
- Cache TTL expired on the clients
- Garbage collection
- Resource heavy query.
2. Zero Tolerance For Failure
GraphQL is at the edge of all the business-critical microservices, so it has to be up and running 100% of the time in order for Dream11 to work. No risk can be taken on this layer so it has to be provisioned for peak traffic for any event. This led to high computing costs for the system.
As traffic increased year on year and we kept adding more features on GraphQL, infrastructure requirements also grew.
In the IPL 2020 final, we had a footprint of 13k instances deployed behind 13 load balancers.
With such a large fleet of EC2 instances, the deployment becomes very complex and time-consuming, and experimentation becomes nearly impossible. This made us relook at the whole architecture again and further optimise the GraphQL layer.
How to measure performance?
“ We can only optimise what we can measure ”
Defining the right metrics to measure performance and identifying correct SLAs on those metrics is one of the critical parts of the optimisation process. Typically performance is measured in terms of latency, throughput, and resource (CPU, memory, and network) utilisation. Having the right tools to measure these metrics quickly is a prerequisite to optimising performance.
Synthetic benchmarking
Doing a load test on a production-grade GraphQL server is very expensive in terms of cost and time. So, we created a synthetic environment that mocked the backend services and generated a dummy load on the GraphQL server.
Tooling
1. Mock API server
We created a mock server to mock API responses from microservices with simulated latency.
2. Custom HTTP client
We have created a custom HTTP load client to simulate the traffic pattern that we get on our production servers.
3. AWS Cloud Watch and Datadog
We monitored the CPU, memory, and latency of the servers using these tools.
Defining Metric For Performance
Defining the correct metric to improve is a very critical part of the optimisation process. For us the goal was to improve the max-throughput ie. the maximum number of requests the system can handle in a second with p50 latency under 200 ms
Upon benchmarking the most commonly invoked queries on a single graphQL server in a load environment, we found out that throughput varied a lot from one query to another, for some of the queries throughput was as low as 50 RPS and for others, it was as high as 500 RPS.
This gave us baseline performance of each of the queries, we could then quantitatively measure any performance optimisations that we would do.
Production Benchmarking
Synthetic benchmarks are good to quickly measure performance relatively across different branches. But the production environment system is much more complex, so we could only extrapolate synthetic benchmarks on production to only a certain extent. To measure performance gain on production we used the canary deployment technique to deploy any performance optimisations.
Production Performance Metrics
We wanted to define a performance metric that we could track on production. But on a distributed system where a number of instances keep on changing and request rates also vary a lot over time, to compute performance improvement we defined a custom metric as


Finding Out What’s Going Wrong Under The Hood? 🧐
In order to find out what’s causing the performance issue in GraphQL, we used the following approaches.
Profiling
We started by profiling one of the production servers during peak traffic with the help of the pm2 enterprise version profiling tool. It allows you to download CPU and memory profiles for a particular process which further can be analyzed using various tools like chrome performance tool, vs code, etc.
CPU Profile
On analysis of CPU profile, we found out that
- On average 20% of total CPU time was being spent by garbage collectors.
- GraphQL validate operation was taking a 3% of CPU time
- Some of the resolver code was long-running


GC profile
In CPU profile analysis we found out that GC was contributing majorly to CPU time, so we wanted to analyze GC further. To analyze GC we used these tools and figured that scavenger GC was happening too frequently.
Inline Caching Heuristic
V8 engine performs a lot of run time optimisation based on certain heuristics. Inline caching is the crucial element to making JavaScript run fast.
We used Deoptigate to identify the hot code which was not being optimised by the v8 engine. We found out a few of the utils functions were megamorphic and were not being optimised by v8.
Analyse APM (Datadog) data
dd-trace (Datadog library for nodeJS) automatically instruments graphQL module. It provides APM data based on queries. Based on this we were able to spot frequently invoked queries.
In order to gauge the complexity of a query, we track the time taken by graphql’s execute operation and the average number of HTTP calls made inside a query.


Micro benchmarking
We benchmarked each widely used library function or pattern against their alternatives using Benchmark.js. Some of the comparisons are described in the next section.
Learnings
- With dataloader and multi-level caching in place, the network was already very optimised.
- Based on our load test results we could see that CPU was the bottleneck for us.
- There were no low-hanging fruits.
Approaches for optimising performance
With all the profiling and benchmarking tools handy we started making small changes and measuring them for performance gain.
1. GC Tuning
In our GC profile analysis, we found that for 3 minutes of load testing,
- the server was spending 30.6 seconds in GC.
- On further analysis, we found that during this period 556 scavenger collections were performed.
Based on this we could see that the problem of the GC is concentrated in the Scavenge collection stage, that is, the memory collection of the Young Generation. The GraphQL server was generating a large number of small objects in Young Generation Space. And hence, triggering scavenge collection. In this way, the problem boiled down to optimising the Young generation to improve application performance.
In nodeJS, the size of young generation space is determined by the flag `— max-semi-space-size` which defaults to 16MB. We tried increasing the max-semi-space-size value with values as 128MB, 256MB, and 512MB. We did a load test with all these values and noticed that at 256MB system was at peak performance. After deploying this optimisation on production CPU utilisation went down by 12%.


2. Fastify Web Server
Fastify is a fast and low overhead web framework designed for NodeJS. On public benchmark, it promises to be 5 times faster than the Express framework. Since all the plugins/middleware used were portable we experimented with Fastify. On production, we got 10% reduction in CPU utilisation.
3. R.curry vs Uncurried
To improve the compositionality of our code we had defined a ton of curried functions using Ramda. But every abstraction has a cost associated with it. On profiling, we found out that the `curry` function was taking up a lot of CPU.


Benchmarks show that removing curry from the code makes it up to 100 times faster. Curry function is at the core of Ramda, almost every function is curried. So from this, we came to the conclusion that Ramda is becoming a performance hog for us.
4. Immutability vs Mutability


In our code, we had written immutable code everywhere. Looking at this benchmark we decided to remove immutability from the hot code.
5. Monomorphic vs Polymorphic vs Megamorphic Functions
V8 engine optimises monomorphic and polymorphic functions at the run time making them way faster than megamorphic functions. We converted a few frequently invoked megamorphic functions to multiple monomorphic functions and observed performance gain.


6. Lazy Evaluation
In GraphQL a resolver can either be an expression evaluating a value or a function that returns a value (or a promise of value). Resolver expressions are eagerly evaluated irrespective of fields invoked in any query.


In the above example if the client queries only id and title then also groupPlayerByType will be executed. In order to prevent such unnecessary invocations, we can wrap these operations inside a function.


This will ensure that groupPlayerByType will be called only when groupedPlayers is queried.
7. Caching query parsing and validations
Graphql performs 3 steps to evaluate the result of each query.
- Parse (Creates AST from the query)
- Validate (validate AST against the schema)
- Execute (Recursively execute the resolvers)
From the CPU profile, we found out that 26% of the CPU time was spent in the validation phase. The server was doing query parsing and validation for every request


But on production, we get requests for a limited set of queries so we could actually parse the query and validate it once for each query type and cache them. In this way, we were able to skip the redundant parsing and validation steps for subsequent queries.
8. Infrastructure Tuning
All requests coming to `https://www.dream11.com/graphql` get routed to multiple load balancers using weighted DNS. Weighted DNS doesn’t guarantee the exact distribution of requests because of DNS caching at the client-side i.e requests coming from a client will go to the same load balancer for a particular period of time (DNS TTL). So even if we assign equal weights to all load balancers there would be some load balancers that would get extra requests, which puts extra load on instances behind the load balancers.
This variance in distribution is directly proportional to the number of load balancers and DNS TTL.
- After all the optimisation we were able to reduce the number of servers that allowed us to reduce the number of load balancers.
- We tuned the TTL value to reduce the variance in traffic distribution.
Results
We started the optimisation project in November 2020 and had only 5 months to figure out performance hogs, optimise, test, deploy and scale down before IPL 2021. We did massive refactors throughout the project and did multiple deployments in this period. Following are some of the results:
Latency
In IPL 2021, overall p95 latency was reduced by 50% in comparison to IPL 2020 which resulted in a better user experience and allowed us to reduce infrastructure footprint further.


GQL time
Average GraphQL execution time is reduced by 70%


Average Performance
We tracked average performance week on week and after all the optimisations and infrastructure tuning it was improved by more than 50%.

Relative Cost
From being the most expensive service by a very high margin, GraphQL is now comparable to other services in terms of cost.

Instance Count

After doing lots of micro-optimisation and some infrastructure tuning. We were able to serve 5M concurrency with 80% fewer instances in the first half of IPL 2021 as compared to IPL 2020. Our daily average cost is reduced by 60% and projecting a similar trend will help us to save more than 1 million dollars during IPL 2021.
Key Takeaways
“ Aggregation of Marginal Gains ”
When we started we couldn’t find any low-hanging fruits. We approached our target of reducing infrastructure from the first principle. We questioned every decision which was taken right from choosing NodeJS as the stack to AWS instance type. We did load tests for the slightest improvement we could think of. Some of the key takeaways from this project would be:
- Instrumenting efficient ways to measure performance is key for optimising performance.
- Multiple optimisations of small improvements can give you larger aggregated performance improvements.
- At the edge layer, SLA for latency can be relaxed.
If you are interested in solving complex engineering problems at scale, join the Dream11 team by applying here.



