

ElasticSearch @Dream11
- Published on
ElasticSearch @Dream11
Scale to serve over 500,000+ events per second, 5 TB+ ingestion capacity and provide logging, search for micro services, security analytics along with anomaly detection
How DevOps team at Dream11 built ‘Elasticsearch as a Service’ for our microservices , security, data services logging and analytics needs in the face of high events frequency and data ingestion requirements
Introduction:
At Dream11, multiple microservices and applications are using Elasticsearch as a core infrastructure engine to solve problems like centralized logging, search capability in applications, storing security related WAF logs and anomaly detection etc. All these use cases involve querying/searching, structured as well as unstructured data with specific keywords at very high events per second with large amounts of logs ingestion per hour/day.
Why Elasticsearch is in Obvious Choice?:
Dream11 was using a SAAS based solution for its centralized logging needs.
Rsyslog was forwarding the logs to the SAAS based provider for our services. However, during our peak game cycle amid popular sporting events, the logging service failed to deliver in time. Events per second -EPS was so high that, the logs to the SAAS provider lagged behind and did not show up in dashboards even after days or weeks. This defeated the very purpose of having the need for real-time logging system as a service. Engineering, DevOps and QA teams were severely hampered and not able to debug issues in time and had to revert to additional monitoring tools or actually having to login to systems for debugging. The SAAS provider acknowledged that due to our scale, they would need to re-architect their solution. This could take couple of precious months! Hence we decided to build in-house Elastic search for our peak scale, data ingestion and internal usecases. This was the rise of ‘ElasticSearch as a Service’.
AWS Elastic search was ruled out after initial analysis due to our high throughput events per second rate(EPS rate) of 200K/second and logging rate of 1 TB to 1.5 TB per day during peak gaming season and matches.
ElasticSearch and FluentD evaluation:
Before implementing the solution, we evaluated different log forwarders and aggregators Log stash, Rsyslog and Fluentd. We appreciated Fluentd’s integration, performance, support and plugins as compared to others.Therefore, we decided to go ahead with an internal ‘Elastic FluentD Kibana’ stack(s) which can be managed within a ‘reasonable’ time and DevOps resources.
Terraform and Ansible were used in building the ElasticSearch stack as a service.
Centralised Logging using EFK

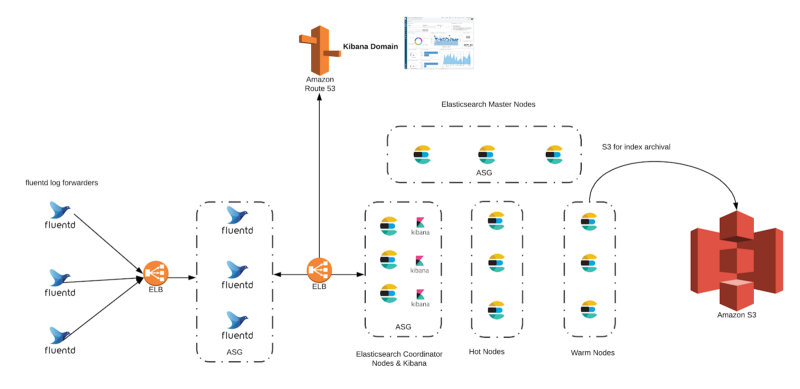
Architectural components : EFK stack at Dream11 is divided into the following components
- Cluster Discovery using discovery-ec2 plugin — Cluster discovery of Elasticsearch is done using ec2 discovery plugin and unique tags of the cluster.
- Log Forwarders ( td-agent ) — td-agent is installed on each and every server and is just used for log shipping to log aggregators
- Log Aggregators ( td-agent ) — Log aggregators process the stream of data coming from log forwarders based on different tags . Data is enriched and sent to Elasticsearch coordinator nodes for indexing .
- Elasticsearch coordinators and Kibana — Elasticsearch coordinator nodes are Elasticsearch node types which act as cluster load balancer. These also have Kibana nodes installed, Kibana just takes single Elasticsearch URL till 6.4.0. This HA of Kibana is maintained using HA of coordinator nodes.
- Elasticsearch masters — These nodes are cluster managers whose work is just to manage cluster
- Elasticsearch Hot Nodes — These are Elasticsearch data nodes with node attribute property set to hot. These nodes have more CPU and RAM nvme SSD for higher write throughput .
- Elasticsearch Warm Nodes — These are again Elasticsearch data nodes with node attribute property set to warm. These nodes stores all indices from previous day to retention period .
- AWS S3 — S3 is used for archival of indices . All indices are kept as per our index retention policies on hot and warm nodes.When the retention period expires they are moved to S3 and deleted from the cluster.
- Curator — Curator is used for keeping indices retention policies , archival , movement of index from to warm , increasing replica count.
- Elastalert Kibana Plugin: Since we are using open source version of Elasticsearch, alerting on Elasticsearch data doesn’t comes out of box . We have used another open source tool, i.e Elastalert developed by Yelp and its Kibana UI plugin developed by Bitsensor to provide efficient alerting framework .
Hardware Configurations: Indexing is resource intensive.So choosing hardware at our scale has been quite cumbersome. There had been a lot of load test to finally come to these hardware configuration and numbers .
- Master Nodes: 3 m5.xlarge instances used as masters are the one which holds all metadata information and perform all cluster management tasks . To avoid split brain scenario odd number of master is used along with ec2 discovery plugin.
discovery.zen.minimum_master_nodes:2 - Hot and Warm Nodes: 5 i3.2xlarge instances are used as hot nodes with node attributes set to hot or warm depending on the node type . i3.2xlarge provides high end machines with 1.9 TB nvme disk which outruns the performance of normal EBS backed SSD disks. 10 d2.xlarge instance are used as warm nodes for index storage upto retention period. d2 instances have 3 instance disks with 2TB throughput HDD eac .
- Client/Coordinator & Kibana Nodes: These are in ASG’s with r5.2xlarge instances which scale according to workload.Each machine is has master, data , ingest set to false to use it as coordinator nodes. Moreover, every machine is having Kibana installed to get rid of SPOF of Kibana .
- Fluentd Aggregators: 5 c5.2xlarge are used for aggregators instances which perform enrichment and transformation.
Index Lifecycle Management : For managing lifecycle of indices curator framework is used . Curator is another tool written in python which can be used for replica management, snapshot and restore etc. Here a sample action file for curator is used for index management
actions:
1:
action: allocation
description: “Apply shard allocation filtering rules to the specified indices”
options:
key: box_type
value: warm
allocation_type: require
wait_for_completion: false
timeout_override:
continue_if_exception: false
disable_action: false
filters:
- filtertype: pattern
kind: prefix
value: logstash-
- filtertype: age
source: name
direction: older
timestring: ‘%Y.%m.%d’
unit: days
unit_count: 1
2:
action: delete_indices
description: “Deleted selected indices”
options:
timeout_override: 300
continue_if_exception: false
ignore_empty_list: True
filters:
- filtertype: pattern
kind: prefix
value: logstash-
- filtertype: age
source: name
direction: older
timestring: ‘%Y.%m.%d’
unit: days
unit_count: 7
Security Analytics Using EFK
Another use case where we are highly dependent on EFK is performing security analytics . We use AWS WAF to secure our websites. To make more out of AWS WAF, analysing WAF logs is a goldmine . AWS WAF can stream WAF logs in realtime using Amazon Kinesis Firehose. Firehose has certain limitation for the sinks (storage of logs).It currently provides only 4 options which are
- AWS Elasticsearch Service
- AWS S3
- Redshift
- Splunk
As we built our own high efficient highly scalable Elasticsearch cluster, we did some POC to push these logs to our Elasticsearch cluster . For this we utilized AWS S3 and it’s event notification service which pushes metadata event in SQS for every new data put into s3 bucket. Using another Fluentd plugin we created consumers of SQS whose capability was to read from SQS metadata and then finally capture data from s3 bucket and push it to our Elasticsearch cluster .
Below architecture diagram describes the complete flow for same.


KPI Monitoring using Elasticsearch and Kibana
Another use case for which we are using Elasticsearch is KPI monitoring where KPI’s are being pushed into Kafka. We are using KSQL and Kafka to transform the data. Kafka Connect Elasticsearch connector pushes this data into Elasticsearch.


Results:
The entire stack(s) were load-tested and tweaks were made constantly to achieve stability and performance. We finally managed to achieve our peak scale requirements and ingestion rate after few weeks of tweaking and testing.We now use Terraform scripts to setup the Elasticsearch stack(s) for any new services or requirements on demand as a ‘service’, much better than what AWS or any other SAAS provider can provide in terms of cost, stability, performance and resources.
Cost savings has been a huge side effect because we manage our ElasticSearch service with the desired high performance, throughput along with customizations that can be done quickly with minimal resources!
Adoption of our stack company wide:
- Since the ‘ElasticSearch as a Service’ proved successful, we used it for our Security Analytics needs as well for analysis of WAF logs. Custom queries were written to scan suspicious IP addresses and block them after review on demand. A separate stack was setup for the security analytics and alerting was implemented using ‘ElastAlert’ for alerting our Security team
- Our stack has then been extended for use for Anomaly detection and Contest fill rate by our DataScience Engineering team. Separate Kibana dashboards and visualisations have been tuned for different requirements and performance.
Metrics:
Estimated ingestion capacity of our ElasticSearch stack(s) was measured at approx 5 TB — 6TB per day, which means capacity to hold approx 150TB to 180 TB data in 30 days! Events per second have been recorded at 500,000 events per second per day maximum as of now and can be scaled further if needed.
Further optimisations and future plans:
- Implementation of Federated ElasticSearch services, so that failure of one EFK stack for a specific use-case does not affect other users of that EFK stack.
- Introducing Kafka as messaging and buffer service. During peak traffic, we have seen that FluentD aggregators can get backlogged and buffers filled very quickly. We plan to introduce Kafka in the architecture while pumping data to FluentD aggregators to absorb any temporary back-pressure problems and store the data on disk. With introduction of Kafka as buffer approach, data can be forwarded at a later point in time to EFK stack without any data loss.
- Authentication and authorization services using SearchGuard.
- Machine Learning module to analyse logs and train models on our security data for automatic alerting on suspicious trends and activities from our application logs and WAF.



